德扑新手入门技巧 | 详细十大攻略
德扑,作为最受欢迎的扑克游戏之一,对新手而言是极具吸引力的挑战。本文将提供十项入门技巧,助你迅速上手并提高胜率。
首先,了解德扑的规则是基础。每位玩家获得两张底牌,随后共享五张社区牌。牌局分为四个阶段,每阶段结束后玩家进行下注。通过这个过程,玩家可组合底牌与社区牌,形成最终牌型。
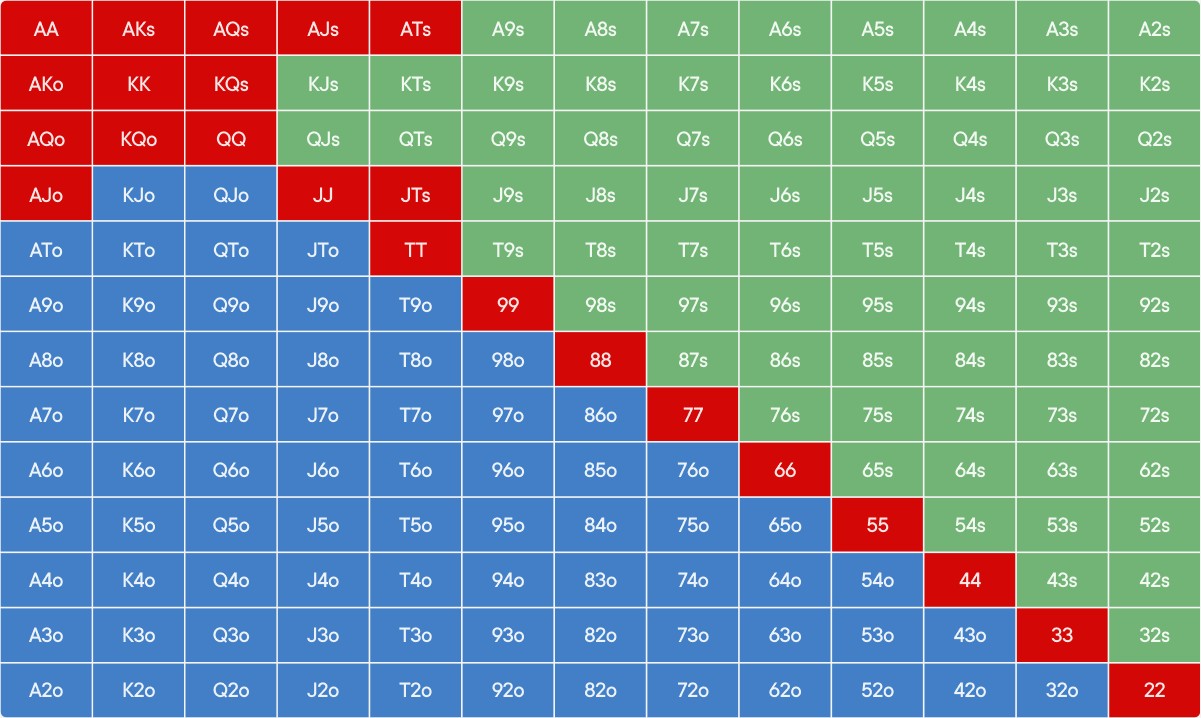
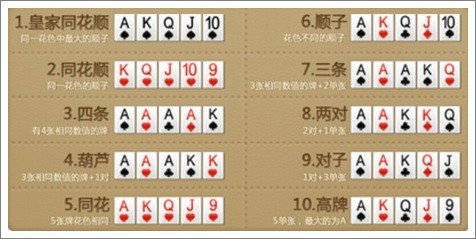
学习扑克牌的等级排名至关重要,从高到低依次为:皇家同花顺、同花顺、四条、葫芦、同花、顺子、三条、两对、一对和高牌。识别最佳牌型(即“坚果牌”)是德扑的关键技能,它能显著影响胜算。
在选择起手牌时,优先考虑底牌的等级和组合,高牌如A-K、A-Q同花,以及高同花如A-K或A-Q同花,都是强力起手牌。正确评估位置和对手行为,根据这些信息调整策略。
初学者应从限注德扑开始,其规则简单且数学计算相对容易。在有限的下注范围内,玩家能更好地控制资金风险,避免大额损失。
在德扑中,始终伽注盲注是明智之举,避免“跛行”(跟住盲注)。这不仅增加了其他玩家的行动压力,还有利于快速积累筹码。
位置影响决策,前面位置的玩家需更谨慎,需要更强的牌才能下注和加注,而后面位置的玩家则拥有更多优势。利用位置优势,做出明智决策。
学会适时弃牌,避免陷入不利局面。在前面位置弃牌是基本策略,而在后面位置,除非看到明显优势,否则应谨慎行事。
避免频繁虚张声势,但也不要过度担忧被欺诈。专注于自己的牌,下注或弃牌,无需过度担心对手的策略。
管理资金至关重要,设定买入限制,避免破产。保持资金稳定,有助于长期游戏。
投资时间学习和研究,从书籍和在线资源中获取知识。阅读专业书籍如《德扑》、《高集玩家的德扑》等,或观看教学视频,参与讨论,不断积累经验。
最后,持续练习是提高的关键。在线游戏提供快速的交伊节奏和同时操作多张桌子的机会,有助于快速提升技能。
通过遵循这些技巧,新手可以更轻松地掌握德扑,提高胜率。不断实践和学习,你的游戏将逐渐成熟。无论是新手还是经验丰富的玩家,这些策略都是有益的开端。
德州扑克第一部分:基础知识与规则
德州扑克第一部分:基础知识与规则
德州扑克,通常简称为德扑或Texas Hold'em,是一种世界上最受欢迎和广泛玩的扑克变种之一。以下是德州扑克的基础知识与规则详解:
一、起源与历史
德州扑克被普遍认为起源于20世纪初的德克萨斯州,因此得名“德州扑克”。早期的德州扑克是一种野外游戏,经常在马车站、赌场和酒吧中进行。随着时间的推移,德州扑克迅速传播到全国各地,并在20世纪后期进一步扩展到国际范围。德州扑克在20世纪末和21世纪初迅速崭露头角,部分原因是因为它在全球电视转播中的普及。二、游戏规则
游戏人数:游戏通常从两名玩家起步,但可以容纳多达十名玩家。荷官角色:每局游戏有一个荷官,负责发牌和管理游戏进程。底牌与公共牌:每位玩家手中发两张底牌(私人牌),五张公共牌依次翻开供所有玩家共享。游戏目标:玩家尝试组成最高的五张扑克牌手牌,以赢得筹码或奖金池。行动选择:玩家可以采取跟注、加注、弃牌和全押等行动。三、手牌组合与价值
德州扑克中常见的手牌组合,按其价值从高到低排列如下:
皇家同花顺:A、K、Q、J、10五张相同花色的牌,无法被打败。同花顺:五张相同花色的连续牌,点数较高者胜出。四条:四张相同点数的牌加一张杂牌,点数较高者获胜。满堂红:三张相同点数的牌加一对其他相同点数的牌,比较三张牌的点数。同花:五张不连续但相同花色的牌,比较最高点数的牌。顺子:五张连续点数的牌,无论花色,比较点数最高的牌。三条:三张相同点数的牌加两张杂牌,比较三张牌的点数。两对:两对不同点数的牌加一张杂牌,比较点数较高的一对。一对:一对相同点数的牌加三张杂牌,比较一对的点数。高牌:没有形成以上任何组合时,根据最高点数的牌判断胜负。四、盲注与发牌流程
盲注:每局游戏有两个盲注,小盲注(最低限注的一半)和大盲注(最低限注),由两名玩家强制下注以建立初始奖金池。发底牌:盲注后,荷官给每名玩家发两张底牌。第一轮下注:从大盲注玩家开始,选择跟注、加注或弃牌。发公共牌与后续下注:依次发出三张翻牌、第四张转牌和第五张河牌,每发一张牌后进行一轮下注,规则与第一轮相同。五、下注与加注规则
下注规则:小盲注和大盲注是强制性下注。
其他玩家需跟注、加注或弃牌以参与游戏。
最低限注由荷官事先确定。
检牌指不下注,通常发生在游戏早期无人愿意下注时。
跟注指下注与当前最高下注额相同。
加注规则:加注以提高当前奖金池的赌注。
加注数量通常至少是当前最高下注额的两倍。
如有玩家继续加注,每名玩家需至少以前一名玩家加注的筹码数量进行加注。
全押指玩家将其所有筹码下注,其他玩家可选择跟注或弃牌。
六、游戏策略
评估手牌:根据手牌强度决定下注和加注的金额。位置优势:晚位置的玩家有更多信息,可更好地做出决策。对手分析:了解对手的下注习惯和策略,判断其手牌质量。心理战:利用下注和加注进行心理战,使对手难以判断您的手牌。综上所述,德州扑克是一种充满竞争性和策略性的扑克游戏,了解并掌握其基础知识与规则是成为一名成功扑克玩家的关键。
浅谈德州扑克AI核心算法:CFR
自2017年AlphaGo战胜世界围棋冠军柯洁后,人工智能技术进入公众视野。棋牌类AI随之在人工智能领域掀起热潮。然而,在AlphaGo之前,人们就已经开始挑战棋牌类AI,从简单的跳棋、五子棋到复杂的中国象棋、国际象棋,再到围棋和德州扑克,数十年来取得了丰硕成果。德州扑克作为不完全信息博弈,不仅要应对复杂的决策,还要应对对手的虚张声势、故意示弱等策略,其博弈树无论是广度还是深度都非常庞大,一直是科学家们想要攻克的高山。在AlphaGo战胜柯洁的同一年,德扑AI DeepStack和Libratus先后在“一对一无限注德州扑克”中击败了职业扑克玩家,实现了不完全信息博弈的突破,而它们所采用的核心算法就是Counterfactual Regret Minimization(CFR)。
1. Regret Matching
CFR算法的前身是regret matching算法,在此算法中,智能体的动作是随机选择的,其概率分布与positive regret成正比,positive regret表示一个人因为过去没有选择该行动而受到的相对损失程度。
1.1算法原理
石头剪子布是最为简单的零和博弈游戏,是典型的正则式博弈,其payoff table如下:
图1·石头剪刀布收益图
Regret matching算法流程在本例中为:
a)首次迭代,player1和player2都以[公式]概率随机选择动作,假设player1选择布,player2选择剪刀。
b)以player1视角,首次博弈结果收益为:[公式]。
c)根据结果收益计算后悔值,[公式]
d)进行归一化处理更新player1的行动策略:[公式]。
e)根据更新后的策略选择动作进行多次博弈,直至达到纳什平衡
f)返回平均策略
核心代码如下(具体代码戳这儿):
1)获得策略方法:1.清除遗憾值小于零的策略并重置策略为0;2.正则化策略,保证策略总和为13.在某种情况下,策略的遗憾值总和为0,此时重置策略为初始策略。
2)训练方法:1.玩选择策略进行博弈,根据博弈结果计算动作效益;2.根据动作效益计算后悔值。
实验结果:
1)当固定对手策略为{0.4, 0.3, 0.3}时
图2·固定对手策略,玩家策略
2)当玩家和对手都采用Regret Matching更新策略时
图3·玩家和对手策略
2. Counterfactual Regret Minimization
石头剪子布是典型的“一次性”博弈,玩家做出动作即得到结果。而生活中显然许多的博弈属于序列化博弈,博弈由一系列的动作组成,上一步的动作可能会导致下一步的动作选择变更,最终的动作组合形成博弈结果。这种序列游戏我们不再使用payoff table表示,而是使用博弈树的形式。博弈树由多种状态组成,边表示从一个状态到另一个状态的转换。状态可以是机会节点或决策节点。机会节点的功能是分配一个机会事件的结果,因此每个边代表该机会事件的一个可能结果以及事件发生的概率。在决策节点上,边代表行动和后续状态,这些状态是玩家采取这些行动的结果。
同样地,对CFR算法中的符号进行若干定义:
算法流程:
2.2实例
库恩扑克(Kunh’s pocker)是最简单的限注扑克游戏,由两名玩家进行游戏博弈,牌值只有1,2和3三种情况。每轮每位玩家各持一张手牌,根据各自判断来决定加定额赌注过牌(P)还是加注(B)。具体游戏规则如下:
图4·库恩扑克规则
以玩家α视角构建库恩扑克博弈树:
图5·先手玩家博弈树
CFR算法流程在本例中为:
a)初始策略为随机策略,假设玩家α抽到的牌值为:3
b)第一轮迭代时,节点选择动作P的虚拟收益计算方法为:[公式]。结合博弈树求解得到:[公式]、[公式]、[公式]、[公式];[公式]、[公式] [公式] [公式]。同理,计算节点选择动作B的虚拟收益为:[公式]
c)利用虚拟收益更新后悔值:[公式]
d)利用后悔值更新策略:[公式],[公式]
e)归一化策略:[公式],[公式]
f)多次迭代,直至达到纳什平衡
核心代码实现:
实验结果:
图6·库恩扑克,玩家和对手策略
3.引申
CFR算法出现时就已经能够解决德州扑克,但面对52张底牌、加注、过牌、河牌等复杂多变的情况使得德扑的博弈树无论是深度还是广度都十分的庞大,对计算资源和储存资源上的开销过于巨大,使得仅仅靠CFR算法攻克德扑十分困难。而CFR后续的研究者们都在费尽心力优化CFR算法的效率,致力于提高计算速度和压缩存储空间。在此,笔者简单介绍几种CFR变种算法,仅做了解。
3.1 CFR+:
与CFR算法不同的是,CFR+算法对累计平均策略做折减,对迭代的策略进行平均时,给近期迭代的策略赋予更高的权重;直观上,越到后期,策略表现越好,因此在都策略做平均时,给近期策略更高的权重更有助于收敛。
在CFR+算法中,counterfactual utility被定义为以下形式:
[公式]
在的基础上,CFR+算法定义了一个[公式],此时CFR+算法中的[公式]为一个累加值,而CFR算法定义[公式]的为平均值,因此CFR+算法中的regret计算方式为:
[公式]
另外,在CFR+算法中,最后输出的平均策略为一下形式:
[公式]
3.2 MCCFR:
MCCFR(Monte Carlo Counterfactual Regret Minimization)是蒙特卡洛算法和CFR算法的结合,其核心在于:在避免每轮迭代整棵博弈树的同时,依然能够保证[公式]的期望值保持不变。将叶子节点分割为不同的[公式],且保证覆盖所有的叶子结点。
定义[公式]是在当前迭代中选择[公式]的概率:[公式]。
定义[公式]表示在当前迭代中采样到叶子节点的概率:[公式]
那么在选择[公式]迭代时,得到的采样虚拟值为:[公式]
通过一定的概率选择不同的block,得到一个基于采样的CFR算法。
3.3结语
除了上述介绍的两个算法外,CFR算法的优化数不胜数,有提高计算速度的Discount-CFR、Warm Start、Total RBP,也有压缩存储空间的CFR-D、Continue-Resolving、Safe and Nested Subgame Solving等。
机器博弈是人工智能领域的重要研究方向。非完备信息博弈是机器博弈的子领域。非完备信息博弈中存在隐藏信息和信息不对称的特点,和完备信息博弈相比,非完备信息博弈更加贴近现实生活中。例如,竞标、拍卖、股票交易等现实问题中都存在隐藏信息和信息不对称。因此,研究非完备信息博弈问题更有现实意义。德州扑克博弈包含了隐藏信息、信息不对称和随机事件等重要特性,它是典型的非完备信息博弈。对其的研究具有非常重大的意义,感兴趣的读者可深入了解。